The use of artificial intelligence and machine learning technologies only makes sense for a company if they profoundly transform the operational experience by improving the company’s KPI performance.
It is therefore important to analyze how a network anomaly found automatically by machine learning impacts operational workflows.
A Network Anomaly (read What is an Operationally Relevant Network Anomaly?) is actionable and compact information resulting from machine learning over very large data sets comprising billions or more data points.
This piece of information has two main operational dimensions:
- Actionability Mode
- Actionability Insight
Actionability Mode describes how the Network Anomaly impacts network operations.
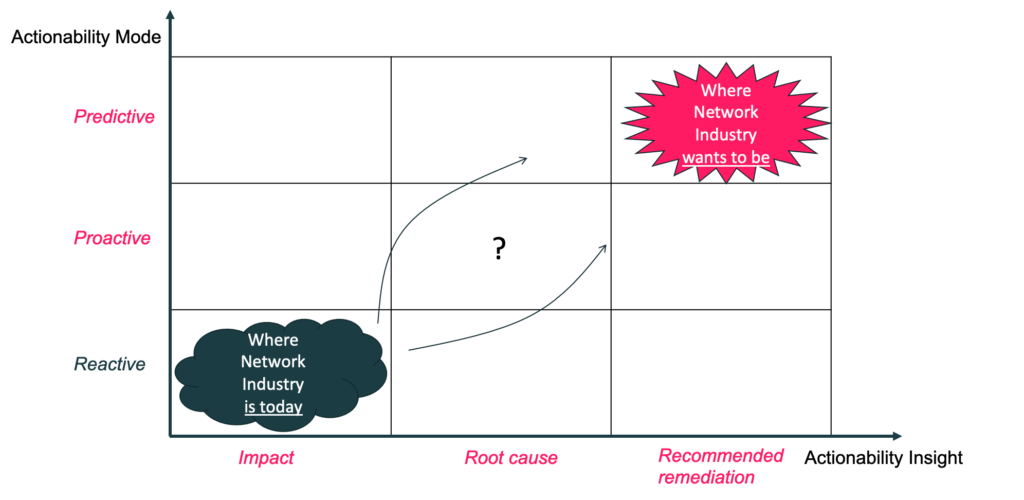
Today the network industry is essentially reactive, where alarms alert operations after applications and end-users have started to be impacted by a failure. Therefore, the alarms typically show up after or at the same time as customer complaints. Further these alarms are often very noisy and mask the actual issue. Such mode is unfortunately quite common in the network industry today.
We will use two common modes used by other industries to describe the Actionability Mode of a Network Anomaly. However, we are going to define them in the context of a Network Anomaly:
- Proactive: the found anomaly is a high fidelity signal that alerts on a network issue or brownout that affects network performance and requires operational attention. It could be otherwise hard to detect issues uncovered by the Network Anomaly, especially when the overall network service is still up and running but there is a grey failure that is beginning to impact the service An example is an abnormal rate of route flapping in a gateway router.
- Predictive: the found anomaly alerts on a misbehavior of one or various components in the network that require operational attention to avoid an expected failure predicted by the anomaly. Such expectation can either be expressed in a binary form (it will happen anytime soon), or it can be expressed as a probability score associated with a timeline, e.g., 70% likely to happen within 2 days. As an example, detecting a subtle abnormal power attenuation (dBm) of an interface lane laser will precede a future outage of that optical component.
Proactive and Predictive modes have some overlap and are often used interchangeably. What matters the most here is that they both contrast dramatically with the legacy reactive mode.
You may have noticed that I have not mentioned auto-remediation yet, or equivalent concepts discussed in the networking industry such as self-healing or self-driven networks. The reason is that although it is certainly related, it is out of scope. Auto-remediation is an automation workflow that will consume the actionability output, therefore it can be considered and discussed separately.
Today the majority of the Network Industry is in the lowest left segment. It is reactive in case of failure and with limited information on the impact.
The aspiration is to become predictive with recommended remediation exposed to the operator.
The big question is how to get there.