Introduction
On December 15th, a major AWS outage was detected by the Augtera Networks hosts Real-Time Multi-cloud Observability (Live AI) 30 minutes prior to AWS giving notice. Live AI is hosted on the Augtera website and is available for everyone to view and use. In this blog we explain how Live AI detected and notified operations teams 30 minutes prior to AWS posting a notice about the outage. This blog will also discuss how Live AI provided valuable outage context for organizations that are using multiple public cloud providers and regions.
AWS Outage Machine Pattern Learning
Augtera is the First Network AI platform. Solutions cover data center, private cloud, SD-WAN, WAN, hybrid cloud and public cloud. The Augtera platform automatically learns patterns in network telemetry and will detect when the pattern is abnormal. The machine learning (ML) can be applied to many different metrics and distributions, for example, traffic, syslog text, and temperature. In this example Augtera is measuring round trip time (RTT) and packet loss data from agents located across the public clouds. In this specific case, an Augtera agent is resident on virtual machines located in each cloud provider. Each agent generates synthetic probe data to every other agent that the Augtera service consumes.
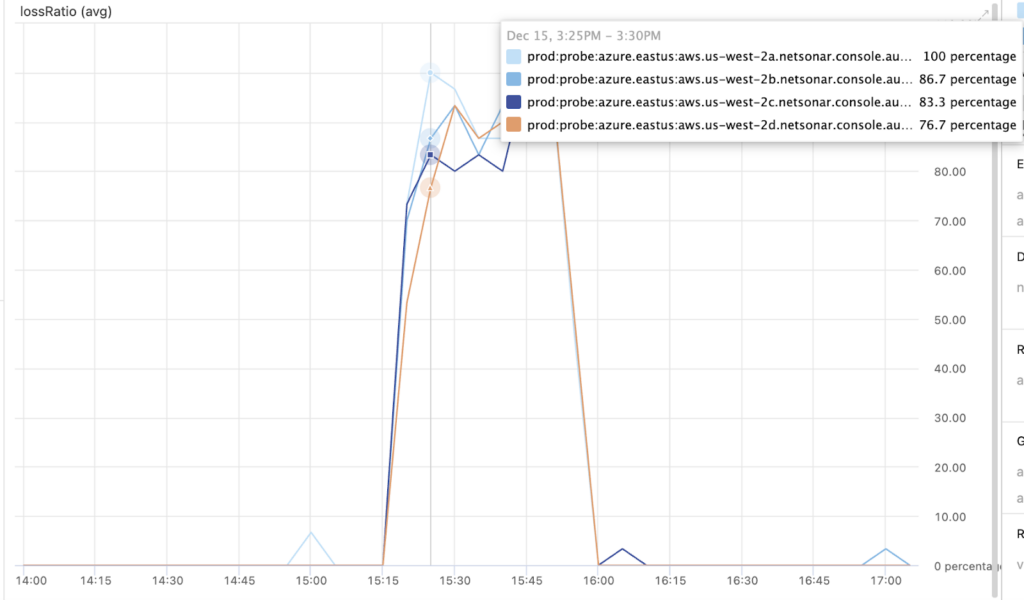
Prior to the AWS outages, Augtera was continually learning the normal pattern of loss and latency between the various cloud providers, regions, and availability zones. Figure 1 is the loss ratio time series data several hours before and after the degradation in the AWS West US-2 region. Currently, Augtera agents are not deployed in AWS US-West-1. At approx 3:15 UTC loss ratio had a dramatic increase and at approx 4:00 UTC it mostly recovered. Not all West US-2 availability zones were impacted equally.
AWS Outage Anomaly Detection
Augtera Live AI had already learned the normal loss between these two cloud regions and produced anomalies as soon as the pattern became abnormal as seen in Figure 2. The AWS outage has a significantly abnormal pattern. However, in many other cases the deviation is not as obvious. Being able to detect subtle and operationally relevant changes in loss or latency is often the difference between proactively addressing an issue and reacting to complaints.

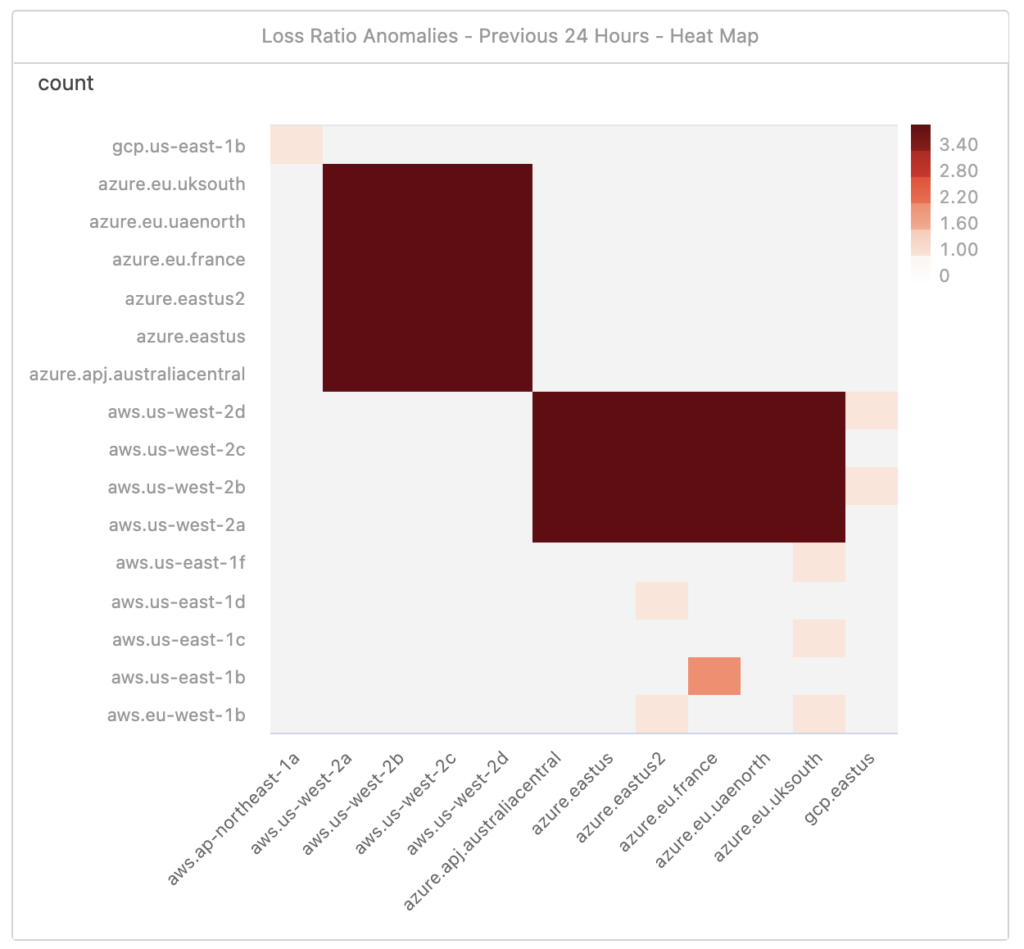
In the Figure 3. heatmap, the vertical column represents the probe data source / sender. The horizontal row is the probe data destination / receiver. A darker shade of color means more anomalies were detected in the time period. A few things become very interesting when looking at the heatmap:
- Probe data from GCP East was not impacted indicating they likely are peering directly
- All Microsoft Azure regions were significantly impacted
- AWS to AWS sites were not as impacted. This might have thrown off some monitoring systems that organizations use.
AWS Outage Conclusion
The AWS outages were detected 30 minutes prior to AWS providing notice due to next generation AI/ML techniques used in the Augtera Network AIOps platform.
The Augtera platform is available via SaaS or On-premises. The agent can be deployed in your network (cloud, data center, branch, etc) for full end to end observability and Augtera can also consume telemetry from your existing sources. To learn more about the Augtera platform and how machine learning can improve your network operations: