AI for operations (AIOps) is transforming network monitoring. Increasing operations data and complexity has led to rising levels of alert fatigue.
Network Monitoring Introduction
All monitoring tends to focus on a device or a software entity. Server monitoring focuses on servers, storage on storage devices, and network on networking devices. Networking has an additional level of complexity, the links that connect devices, the protocols between devices, and the sessions that carry application traffic over networks.
The first step in monitoring is to decide what outcomes are desired. The second step is how to measure those outcomes.
There was a time when simply ensuring network objects (devices, links, interfaces…) are available, was sufficient. Software as a service, multi-cloud, hybrid cloud, work from home, and other business / IT trends have put increasing focus on performance.
Network operations teams need to determine availability and performance for all network objects, layers, and application flows and sessions. They need to ensure that the network is not impacting customers and applications teams.
Network Monitoring with Machine Learning Models
Thresholds take a set level and alarm when not met.
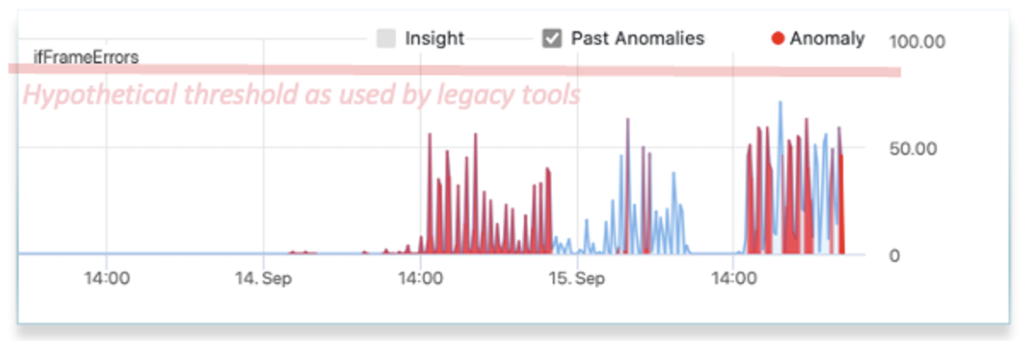
False negatives occur if the level is set too high. False positives when set too low. The challenge of setting thresholds increases as the number and variety of network objects and distances increases. Using thresholds has led to alert fatigue. Operations teams ignoring alerts and/or not being effective.
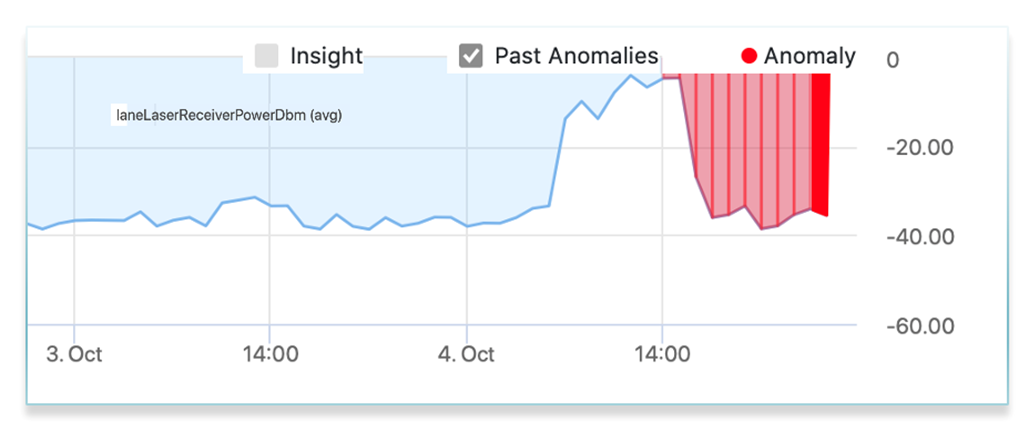
There are some metrics for which static thresholds may be still relevant. However, for many, they are not.
Network monitoring with AIOps uses machine learning models to reduce noise and administration burden. Machine learning models that understand the patterns and distributions in networks, algorithmically determine if an anomaly has occurred.
Read more about ML models vs. thresholds.
Tool consolidation
A significant challenge that has emerged is tools proliferation. Every vendor and every data source / type and a different tool. The barriers to rapid incident root and mitigation are high, often taking 40 minutes or more. When data sources / types are consolidated, anomaly detection, correlation, incident root determination, and intelligent automated ticket creation can be achieved with one platform.
Operations teams replace multiple network operations tools (NetOps Tools) with a single Network AIOps platform, that auto-correlates multiple data sources / types and rapidly determines incident root.
Conclusion
Network monitoring platforms need to:
- Be multi-vendor and multi-layer.
- Use Network AIOps to reduce alarm fatigue.
- Quickly determine the overall health of a network, and whether application teams and customers are being impacted.
Network AIOps tools already ingest data to build their models, monitoring is inherently what they do. They also execute network observability and Network AIOps.