
The purpose of this page is to explore the real-world application of AI in networking, with a focus on AI in Network Operations (NetOps) & AI in network management. Content consists of external references to AI topics and Augtera written content. The intent is to provide a view of AI that is not entirely through an Augtera lens.
What is AI?
Artificial intelligence is often described as the branch of computer science that seeks to mimic human intelligence. Increasingly, it is being defined as computational approaches to solving problems and achieving goals, regardless of whether the approaches are biologically observable.
As applied to network operations, the goals are:
- Incident mitigation as fast as possible
- Recommended and/or executed remediations (Note 1)
- Prevention of future incidents
Further reading: What is AI? / Basic Questions, Professor John McCarthy
Video: What is Artificial Intelligence, Hubspot Marketing
Why is AI applicable to Network Operations / Network Management?
Billions of data points a day are received by network operations teams. Even a fraction is not humanly observable, let alone comprehendible. Best case, a small portion can be used in monitoring dashboards and as forensics during triage. Also as part of longer-term analysis. Human analysis often involves manual correlation across many different operations tools, in addition to chasing down irrelevant, redundant or false alerts. This is time consuming, impacting network availability and performance.
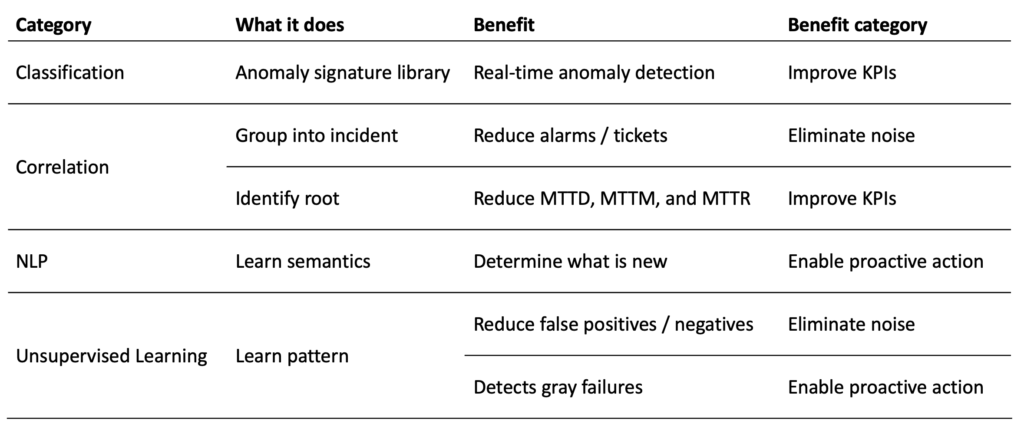
The next significant step forward in network operations is the real-time analysis of streaming data as it is received. Automatically detecting anomalies, grouping them into related incident roots (Note 2), and notifying operations consoles, ticketing systems, and automation systems. Notifications should be noiseless, operationally relevant, current, and emerging issues impacting application / service availability and performance.
Both AI in NetOps processes and AI in Network Management are applicable use cases.
How is AI for Network Operations / Network Management different than standard AI?
Off-the-shelf, open source, and/or academic AI is often developed to study large datasets without consideration of real-time processing. This type of AI also commonly studies data distributions that are different than network distributions. Lastly, AI for NetOps must be integrated into the processes and workflows of NetOps to be effective.
Real-time processing requires high-performance code, but more importantly, high-performance algorithms. In addition, while some AI projects have access to significant compute / storage resources, Enterprises are sometimes severely limited in the resources they can procure for network operations tools. As a result, real-time AI for NetOps has to be both high performance and high efficiency.
Off-the-shelf and Academic AI often deals with well-known distributions like a bell curve. Network patterns vary greatly from interface to interface and network to network. In addition, patterns vary from use case to use case. As a result, network-specialized algorithms and models are required for NetOps AI / Network AIOps. (Note 3).
AI that does not achieve a NetOps relevant goal is just a science project. Network Operations teams can either wait until customers / application teams call them notifying of problems, or operations teams can implement processes that allow them to mitigate problems before customers / application teams call. For many teams, the latter has seemed an impossible goal. However, with AI, Network Operations teams can automate the creation of high-fidelity, operationally relevant trouble tickets, before calls start coming in. Skilled operations / SRE resources can be quickly scheduled / notified in less than a minute.
Is Unsupervised Learning Applicable to Network Operations / Network Management Use Cases?
Yes.

Unsupervised learning identifies patterns in data without any supervision. In other words, without any guidance as to what a pattern is. Such guidance is referred to as a label. For example, this pattern is normal for backbone traffic, or another pattern is normal for edge traffic.
There are two challenges with network use cases. Firstly, there are not many publicly available labeled datasets that are applicable to network use cases. However, an even greater challenge is that patterns vary from interface to interface, from network to network, and even from network object to network object.
As a result of these challenges, use of unsupervised learning is common in networking use cases. Patterns are detected from the data, without guidance/labels, using algorithms and models, that are specialized for networking. (Note 3).
Video: Supervised vs Unsupervised Machine Learning: What’s the difference? Eye on Tech
Is Supervised Learning Applicable to Network Operations / Network Management Use Cases
As discussed in the above section on unsupervised learning, there are often challenges to using supervised learning in network use cases. However, there may be increased use of supervised learning in the future, and there are techniques used today that have a similar outcome as supervised learning.
If through experience we gain some insight about a pattern, we may then create a classifier that looks for that pattern and takes a customer defined action. While this is not the classic definition of supervised learning, the classifier is analogous to labeling a pattern. A classifier created/discovered by one customer may be distributed to other customers. The additional customers could be considered too have received a labeled pattern, with some insight into what that pattern is.
In terms of the classic understanding of supervised learning, natural language processing (NLP) implementations can use both supervised and unsupervised learning. As use of NLP grows, more supervised learning may be used in these implementations.
Does AI Use Thresholds to Detect Anomalies?
Some network characteristics can be managed with a common threshold across the entire network. For example, a network operations team may decide to have a policy that anytime there is packet loss of X%, an alert should be raised. Some AI/ML tools for networking can support this type of traditional threshold, in addition to AI/ML techniques.

However, there are many anomalies for which thresholds generate significant noise: either false positives or false negatives, depending on how they are implemented. These include optical levels, latency, and jitter. For these network characteristics, network specialized AI algorithms and models have better results.
AI algorithms specialized for network use cases, are more robust in the presence of transient spikes, and better understand patterns, including seasonal patterns. They produce less false positives without creating false negatives. (Note 3).
How can AI Prevent Future Network Incidents?
One of the benefits of using Machine Learning Algorithms is the ability to detect increasing degradation. These are often referred to as “gray failures”. Operations teams can proactively address gray failures and concerning trends before a failure occurs.
As AI in Networking reduces noise, and focuses resources on what is operationally relevant, network operations teams will shift more of their time to performing proactive prevention. In addition, there is likely to be improvements in AI-based recommendations.
Can AI Understand Any Network Operations / Network Management Data?
Like many data science and networking tools, there needs to be a layer that understands the format of data received. This layer often translates what is received into a common format used by the AI analysis functions. This translation to a common format is referred to as normalization.
Formats like SNMP, sFlow, and IPFIX are usually normalized by logic that understands their structure. There is a significant amount of innovation going into how syslog is processed, but it too can be normalized. Data received in formats like JSON, can be fairly easily mapped to the normalization format.
There is no inherent limitation on what networking data can be ingested by an AI tool, but different tools will support different data depending on what use cases they are focused on. That said, one of the characteristics of AI-based tools is they tend to ingest a wide range of data types than preceding tools, so they can generate insights from correlating across them.
Is Correlation Used in Network Operations / Network Management Use Cases?
Yes.

Long before AI was used in network use cases, there was a well-known saying in statistics, correlation is not causation. Simply put, while it may be common for A to be true when B is true, it does not mean that A is the cause of B.
For example, this link provides a number of examples of trends that appear to be similar, even though there is likely no causation. One example given is the number of people who died by being tangled in their bed sheets and the amount of cheese consumed. For this reason, and because of the multi-layered nature of many network anomalies, any claim about causation has to be carefully understood.
What correlation can used for is identifying relationships and associations. For example, it may be possible to conclude that there is a high probability that multiple events / anomalies are the result of the same root problem, even if the root cause is not yet known. Additionally, when multilayer physical and logical topologies are known, it may even be possible to have a good assertion about what network object is the root if the incident.

The entirety of information related to an incident is often spread across multiple data sources: SNMP, Flow Data, Syslog, etc. Correlation is a way of bringing a more holistic view of an incident, into better focus, in an automated way, so network operations teams do not have to manually create this view by going from one network operations tool to another. In so doing, operations teams can start working on mitigation and remediation much sooner.
How is AI making a difference in Networking?
The front-end of real-time AI is a high-performance big data ingestion and normalization pipeline which, along with high-performance / high-efficiency algorithms, makes possible the analysis of multiple data sources / types, and ultimately a single platform that can do what multiple tools do today.
When based on a multivendor / multilayer network model that understands network objects, relationships, state, and behavior, AI can identify the root of an incident. Dramatically reducing time to mitigation and repair.
Correlation, customer policy, ML models instead of thresholds, combined with other techniques is reducing incident notifications / trouble ticket creation by a factor of 10+.
NetOps teams are becoming proactive in multiple ways. They are seeing gray failures before they become downtime, they are working on incidents before customers / application teams call, and they are shifting time to activities that will lead to an increase in overall reliability.
Automated ingestion, network model discovery, anomaly detection, correlation, policy, and notification combine in a workflow that battles alert fatigue, reduces the interrupts to network operations, allows network operations to be more proactive, and improves KPIs. Network Operations teams go from being the first place fingers are pointed to be last place.
Notes
Note 1
Not all remediation can be software-controlled, for example the replacement of physical components. In addition, remediation can be operationally complex. However, there are areas where AI can improve remediation.
Note 2
Noise can be significantly reduced when all related events / anomalies are grouped into a single incident notification / record.
Note 3
Network-specialized algorithms perform better than general-purpose algorithms.