The question is not just a teaser. There is a fundamental reason for introducing this blog in this manner.
Because any SD-WAN implementation is a vendor specific mix of standard and proprietary building blocks, breaking the symbiotic relationship that network engineers had with network technology in the past.
Previously, network engineers were building an entire network stack that included connecting links to the router, configuring interface IPs, configuring IGP, BGP peers, dampening, timers, BFD, queues, MPLS LSPs with RSVP FRR or LDP, MPLS VPN route distinguishers, route targets, and many more.
Each component was documented by vendors and industry standards, with troubleshooting guides, and years of experience manipulating the same network constructs.
With SD-WAN, the network engineer becomes an end-user, using an abstracted Graphical User Interface (GUI). This removes a lot of complexity – As well as a lot of network awareness.
Now the network engineer relies on the SD-WAN GUI to detect service failures. All SD-WAN GUIs are designed to provide failure detection such as CPE up/down, tunnel up/down, and similar alarms. In that context network engineers are most of the time informed at the same time as the end-user service impact occurs.
But network realities are the same as before: a network may cough before falling down.
Detecting network “cough” is the hard thing to achieve in SD-WAN networks.
In the first part of our SD-WAN blog series (Is AI/ML the Holy Grail of SD-WAN SASE Networks?) we were touching on SD-WAN infrastructure grey failure detection. The objective being able to detect among noisy events abnormal patterns highlighting SD-WAN control plane or data plane instabilities before a failure occurs.
Let me expose a very concrete case we have experienced with a global 500 enterprise, deploying Augtera Network AI platform in a Cisco Viptela technology environment. As with any SD-WAN vendor, the provided management tool (GUI) offers visibility on connectivity and informs if a site has lost reachability. In other words, a reactive approach is the standard operational workflow with such technology.
However the customer wanted to detect from any low level signal in the network if any degradation was happening before a failure eventually occurs.
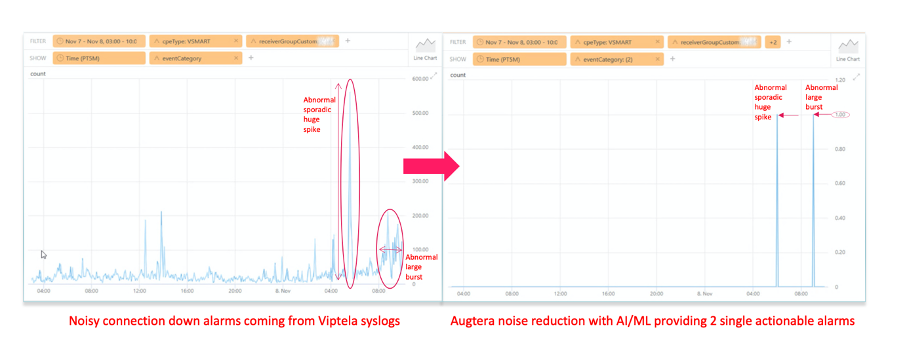
As we explored the data provided in SD-WAN logs, such as control plane connections and data plane BFD up/down events, together with the customer, we realized that surprisingly these protocols could generate 1M events per day in a network with 1000+ CPE devices in nominal condition, i.e. when the network is working as expected.
The customer however observed during past service impacting network incidents that the rate of such control messages was showing spikes sometimes hours or days before the actual network failure. However the customer could unfortunately not capture these rare events with traditional thresholds provided by legacy NMS ingesting logs. This inability is due to two fundamental issues. First, the control plane and BFD events were very noisy making it hard to set what a threshold should be. Second, the network was continuing to expand as they added more sites causing the noise floor to continue to grow higher. The customer found they were continuously trying to tune their threshold without success.
That was before Augtera was used.
Thanks to machine learning, it is now possible to detect when the stability of the network is compromised, thus providing actionable insights for proactive operations.
See below an example where Augtera transforms 1000s of connection flaps into 2 single actionable alarms (aka machine learning anomalies) after eliminating the noise.
For more information, please read the Manufacturing and Healthcare Industry Case Study we just published.
To have a 30 minute discussion with an engineer on how Augtera Network AI can help with your network challenges please click the contact us link and someone will contact you. Thanks for reading our blog.