There is likely a long journey ahead to fully autonomous networks, as Augtera Networks CEO Rahul Aggarwal recently commented in a Packet Pushers Tech Bytes podcast.
However, the focus and results of Network AI on automating network operations has implications for autonomous networks.
Autonomous Networks and Performance Expectations
Arguably, no idea is more embedded in the Internet psyche than the end-to-end principle. The idea that characteristics such as reliability and security should be guaranteed by the communicating end nodes. Yet, when the application team comes knocking on the network operations door, they are not there to discuss the end-to-end principle or their own responsibility in guaranteeing great application experiences, they are there to discuss the network’s responsibility. Such is life.
Performance expectations may well be the issue that ultimately challenges the end-to-end principle. If all anyone cared about was availability, with a few delays here and there being ok, then having many (real) path options is probably good enough. However, in a world where performance does matter, dense topologies, as we see in Data Centers today, create their own challenges. For example, which one of the many paths between A and B is experiencing intermittent optical errors, fabric congestion, flapping or anomalies.
In a world where performance and great customer / application experience matters, as they do in a cloud service and digital transformation world, autonomous networks also become that much harder to achieve. Any IP network with large (real) path optionality is practically autonomous by default, without having to do much at all1. However, throw in a few latency and packet loss constraints, then all of sudden, autonomous networks take on a different flavor.
Automating Network Operations & Autonomous Networks
At Augtera Networks, we are focused first on Automating Network Operations. The chain of events from data ingestion, through anomaly detection, noise elimination, operations policy, mitigation, remediation if possible, and the automated creation of a trouble ticket that often allocates a skilled human resource to determine if a cable, transceiver, switch/router, or other, in the physical hardware world, must be replaced. However, while the outcomes are network operations centric (faster response, less incidents, improved KPIs), how these play into long term network automation should be clear as well.
Above, when I said an IP network is essentially autonomous by default, I was saying in a world where finding an available path in the topology is sufficient, then the control plane is sufficient2. However, if the goal is to find a path in the topology with desired performance, the control plane may not be sufficient. All that other stuff outside the control plane suddenly becomes important. For example, is a control plane going to analyze streaming flow data to determine which applications might be experiencing performance issues as a result of TCP anomalies caused by fabric congestion? If not, then there is a universe of network operations data that is going to play an important role in Autonomous Networks.
High-Fidelity Signals Are Also Important for Autonomous Networks
There are numerous ways in which latency and packet loss could be measured and could be integrated into the control plane. However, the reality today is that networking teams are showing significant interest in agents that do latency and packet loss measurements, reporting to a management/operations system. However, that is just the foundational step.
For example, say an operator deploys agents and collects data. Now what? How is the operator going to determine if the latency is ok? Can’t really use a common latency threshold across all links, like for example might be ok with packet loss. Links and paths vary in distance, hops, and other variables. There needs to be a high-fidelity way of determining that there is, or is not, a latency issue. High-fidelity includes eliminating false positives.
High-fidelity signals are incredibly important to network operations teams. However, they will arguably be even more important to autonomous networks. To operations teams’, high-fidelity means less alert fatigue, more confidence that action is needed, and the ability to focus limited resources on “real” incidents.
However, consider autonomous networks. Imagine a network decision function receiving low-fidelity signals from outside the control plane, and potentially multiple low-fidelity signals from different data sources, analysis systems, and tools? Dante’s Inferno within a Divine Comedy! Perhaps that is why auto-mitigation and auto-remediation are still in their early stages in many networks. Receiving high-fidelity signals is job one for all future network automation.
Prevention of future Incidents
If high-fidelity signals is job one, then job two is preventing future incidents. Tools vendors can help network operations teams respond faster, but over the long run, that may just mean running faster on the same hamster wheel. What network operations teams need is a different hamster wheel, one that reduces the total number of incidents, “today”, and in the future.
If as an industry we get good at responding very fast, to an ever-increasing number of incidents, then I am not sure that is a good scenario for autonomous networks. My intuition is that network operations, for sure, and probably autonomous networks as well, need a path to preventing future incidents. We tend to believe that control processes have all the CPU and Memory they could ever need. Every now and then they surprise us.
Sustainable Outcomes
Lastly, the conditions for creating good applications experiences needs to be sustainable. A word like sustainable is overloaded with many different inferences, and it is no accident I chose that word. However, in a purely operational sense I refer to the long-term maintenance of good conditions through incident prevention, planning, architecture, and alike.
Conclusion
At Augtera Networks we are achieving high-fidelity signals with classifiers for well-known anomaly signatures, Machine Learning algorithms that reduce false positives, topology-based correlation that is eliminating the noise from related alerts, customer-defined policy that specifies what is operationally relevant to the customer, and more. We are also finding rare log messages that can precede outages, and detecting gray failures before they become significant incidents.
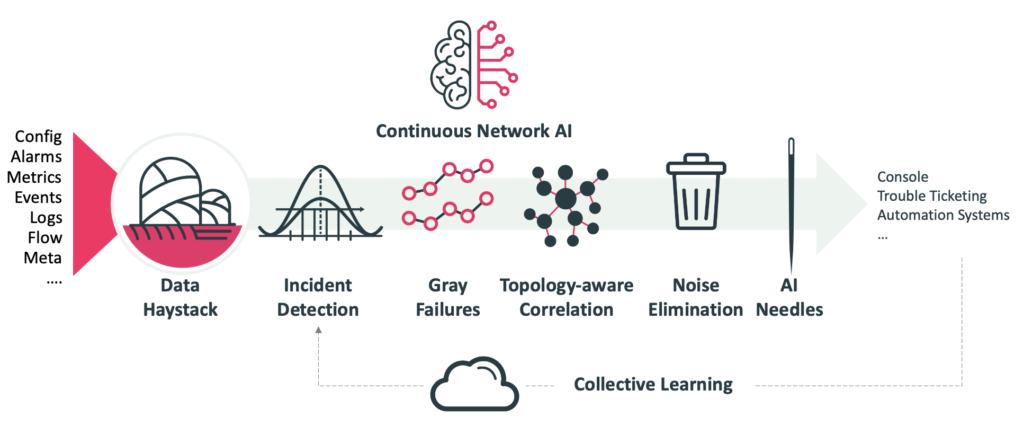
AI/ML is going to make significant contributions to fidelity, prevention, and sustainability. The first significant beneficiaries may be network operations, as we think of network operations today. The ultimate win though, may be for autonomous networks.
Related Links
Notes: 1 – Notwithstanding appropriate design/architecture constructs to keep the control plane humming, etc.
2 – Assuming their is sufficient underlying physical path diversity etc.