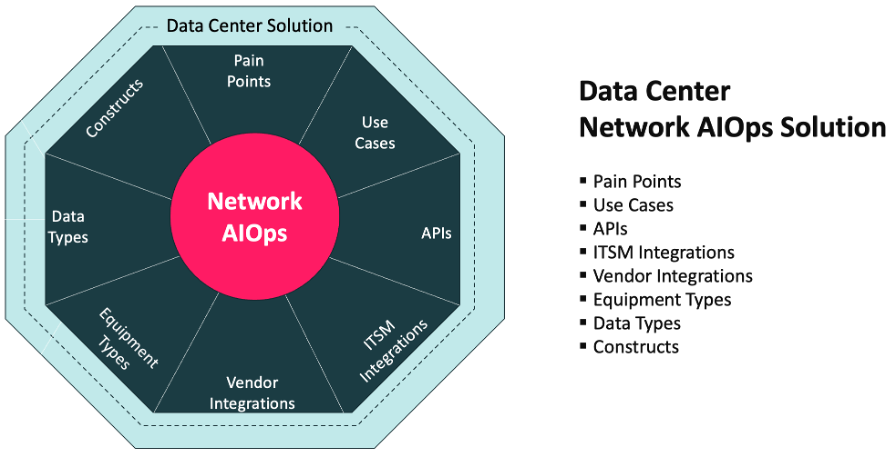
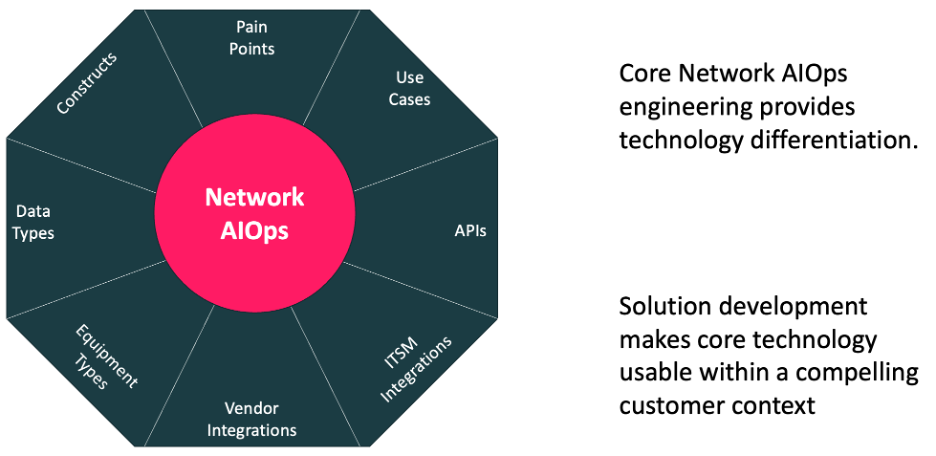
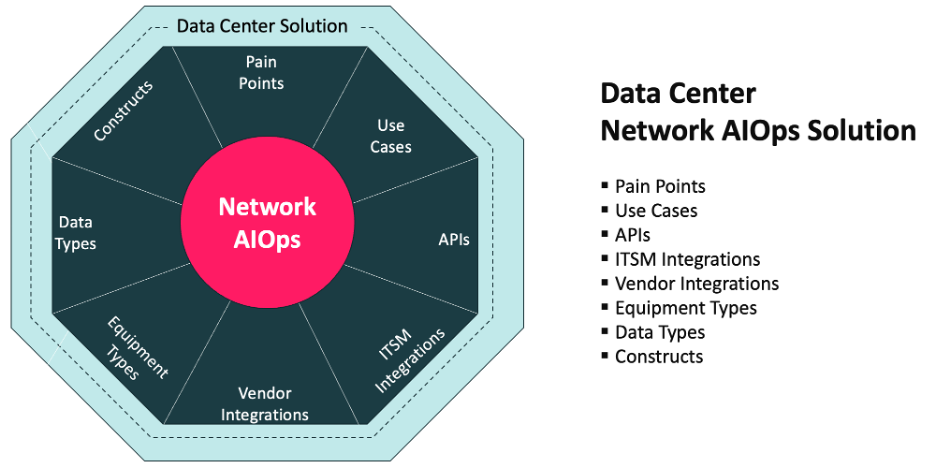
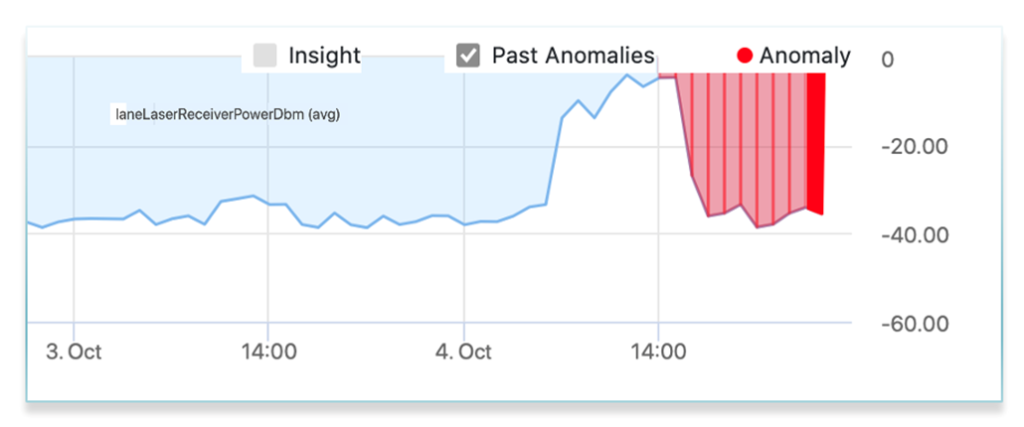
Data Center network internists are needed because of the complexity that has arisen from modern architectures. Router specialists, switch specialists, etc. remain critical, however, a new type of skill and network operations platform is required to address today’s complexity, just as it is in medicine, when an issue is larger in scope than a single organ.
What is a Medical Internist?
Internists are specialist internal medicine physicians, trained specifically to care for patients with multiple simultaneous problems or complex comorbidities. Treatment is provided for undifferentiated presentations that do not easily fit within the expertise of a single-organ specialty. Examples include dyspnea, fatigue, weight loss, chest pain, confusion, or change in conscious state.
We use this medical role to make the analogy of a data center network internist.
Data Center Network Internist Relevance
The human body and Data Center architecture have many commonalities. The body contains organs such as heart, lungs, liver, stomach, gallbladder, interconnected by various “network-based” systems including arteries, veins, and capillaries. There is also a nervous system, musculoskeletal system, respiratory system, and digestive system.
A datacenter consists of:
- A facility designed to optimize space and environmental control.
- Core components including routers, switches, firewalls, load balancers, storage, & servers.
- A multilayer network including optical, Ethernet, IP, underlays, overlays, SD-WAN, & segmentation.
- Support infrastructure including UPS, HVAC, and physical access surveillance.
Each core component can be broken down into multiple network constructs with their own sub-systems. For example, a router has line cards, physical ports, queues and optical lanes.
Data Center networks show an even stronger analogy to the human body than WAN networks. Data Center networks are highly meshed and offer numerous connectivity paths. This makes finding an insight needle in the operations data haystack, more challenging than other network domains.
Data Center Internist Key Attributes
Applying key attributes of Internal Medicine to Network Operations:
- Holistic. Ingesting and processing data from:
- All elements, not just switches. See above.
- Multiple data types, including SNMP, gRPC/gNMI/OpenConfig, syslog, probes, sflow, & meta
- All vendors, including Cisco, Juniper, Arista, (Dell) SONiC, F5, Palo Alto and other standards-based elements
- Model based:
- Semantic understanding & interrelationships are critical, otherwise correlation will be limited.
- Network model and knowledge should be part of the workflow.
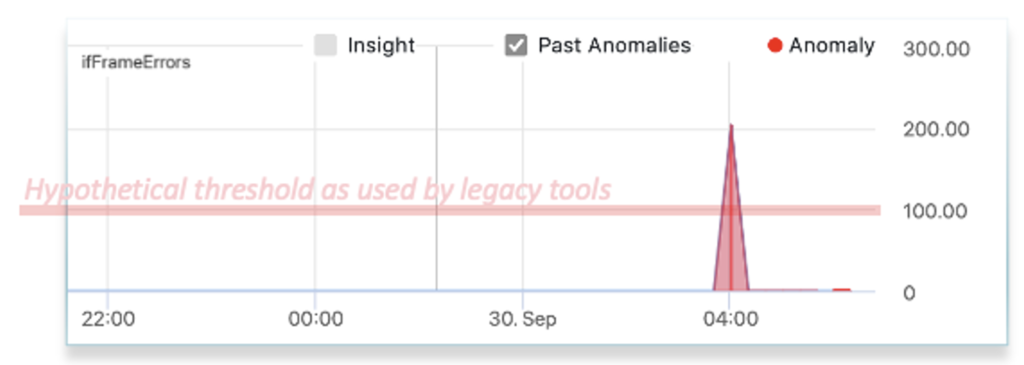
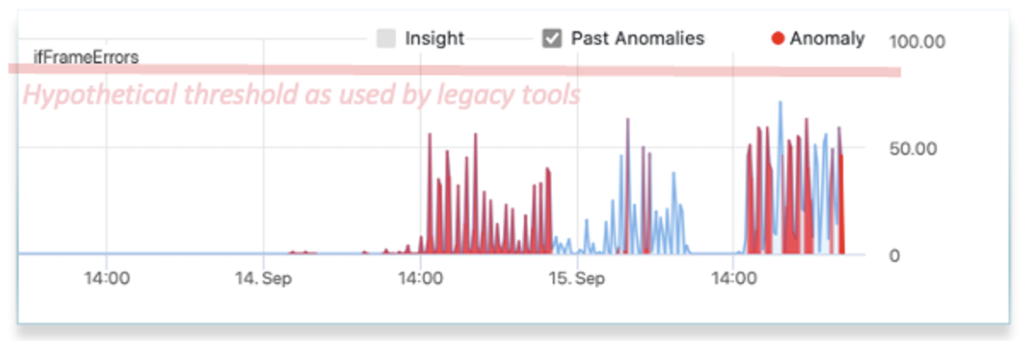
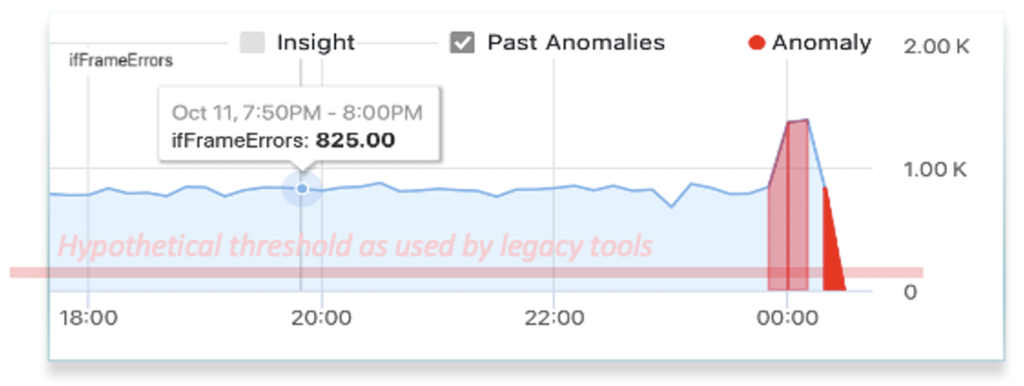
- Automatic Anomaly Detection:
- Efficient techniques to detect abnormal behavior within large streams of metric and event data
- Accuracy to minimize false positives and false negatives.
- Correlation technique choice has profound consequences in both medical and networking.
- Real time big data pipeline:
- We can imagine the impact if all metrics and events could be observed for a human body.
- While this is not achievable today for medicine, it is for Data Center Networks.
- Proactive and predictive:
- In networking, an analogous concept to “disease prevention” is eliminating reactive network operations to become proactive and predictive. For more thoughts on this point, read: Actionability in Network Operations: What does it mean for me?
Today, the datacenter “internist” either does not exist, or is powerless. The job that maps best to this role is the Site Reliability Engineer (SRE).
Transforming Data Center Operation Using Internist Attributes
As depicted in Figure 1 below, this analysis leads us to an AI/ML Datacenter Operation Radar Chart that will transform the way we operate datacenter networks to achieve unprecedented goals: automatically finding needles in a haystack, model-based autocorrelation, proactive/predictive observation, and fast troubleshooting reducing time to innocence.
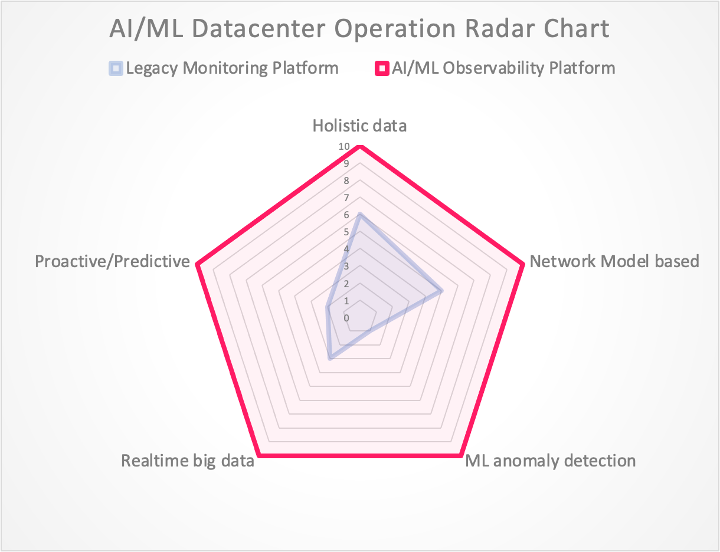
Figure 1: AI/ML Datacenter Operation Radar Chart
This chart also helps us to realize the gaps we have with legacy monitoring platforms and precise evolution objectives as well as market expectations.
Conclusion
Modern data center network architectures have shifted complexity from equipment to operations. As a result, existing approaches to anomaly detection, mitigation, and repair are breaking down. In addition, there is neither the cycles nor the techniques for doing preventive disease control – going from being reactive to proactive and preventative.
Specialist single-organ physicians are critical in medicine. A different skill is required when the problem is more complex than a single organ. SREs play a similar role in networking as does Augtera’s next-generation Network AI platform.